

Cluster and level algorithm
Resources, operations and buffers are connected with each other with loads and flows. An operation has a collection of loads and flows. Each flow establishes a connection with a buffer, and each load a connection with a resource. The entities thus constitute a network graph. In this network context we define clusters and level as follows.
A cluster is a set of connected entities. When a network path across loads and flows exists between 2 entities they belong to the same cluster. When no such path exists they are effectively situated in independent partitions of the network.
Clusters allow us to group entities and are very useful in multithreaded environment: since the clusters are completely independent we can use different threads to solve each cluster as a separate subproblem.
Material flows in the network have a direction. This creates a sense of direction in our network which is expressed by the level concept. An operation consumes and produces material, as defined by the flow entities (aka bill of material or recipe). In this context the level is a number that is defined such that the level of a consumed material buffer is always higher than the level of the produced material buffer. The demand is normally (but not exclusively!) placed on the material buffers with level 0, and the level number increases as we recurse through the different levels in the bill of material. Raw materials have the highest level number.
The level and cluster number are helpful for the various solver algorithms. They provide valuable information about the structure of the network.
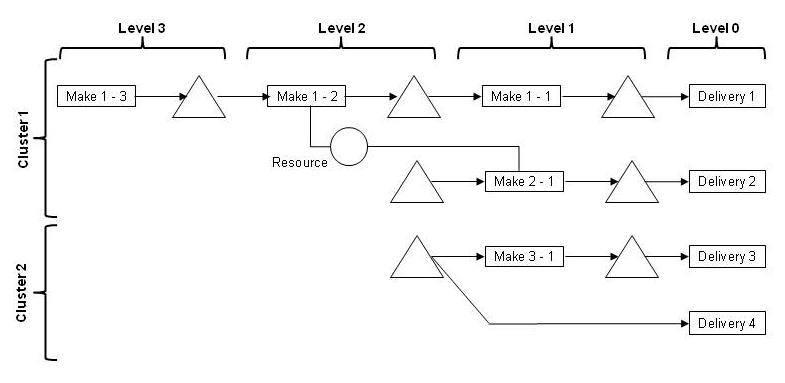
The algorithm used to compute the level and cluster information is based on a walk through the network: We select an unmarked operation and recurse through the loads and flows to find all connected entities, updating the cluster and level information as we progress.
For efficiency, the algorithm is implemented as a lazy function, i.e. the information is only computed when the user is retrieving the value of a level or cluster field. The algorithm is not incremental (yet), but computes the information for the complete network in a single pass: a change to a single entity will trigger re-computation of all level and cluster information for all entities.
The pseudo-code of the algorithm is as follows:
// Initialisation
Lock the function
Reset the level and cluster to -1 on all resources, operations and buffers
Reset the total number of clusters
// Main loop
Loop through all operations
// Check the operation
If the operation has no producing flow
Activate the level computation
If the operation isn’t part of a cluster yet
Activate the cluster computation
Increment the cluster counter
If both cluster and level computation are inactive, move on to the next operation
// Recursively process the operation stack
Push the current operation on the recursion stack, with level 0 or -1
Loop until the stack is empty
Pop an operation from the recursion stack
Pop the value of cur_level from the stack
// Detect loops in the network structure
If the operation was already visited in the recursion loop
Move on to the next operation
Loop through the sub operations and super operations
If their level is less than the current level
Push sub operation on the stack, with the same level as the current operation
Set the level and cluster fields
Else if cluster is not set yet
Push sub operation on the stack, with -1 as the level
Set the cluster field
Loop through all loads of the operation
If level search is active and the resource level is less than the level of the current operation
Update the level of the resource
If the cluster of the resource is not set yet
Set the cluster of the resource
Loop through all operations that are loading the resource
If operation cluster isn’t set yet
Push the operation on the stack, level -1
Set the cluster of the operation
Loop through all flows of the current operation
If this is a consuming flow and level_search is active and the buffer’s level is less than the current level +1
Level recursion is required
If level recursion is required or the cluster of the buffer is not set yet
Set the cluster of the buffer
Loop through all flows connected to the buffer
If it is a consuming flow and level search recursion was enabled
If operation level < level + 1
else if operation cluster isn’t set yet
Push the operation on the stack, level -1
Set the buffer level to level + 1
else if operation cluster is not set yet
Push the operation on the stack, level -1
Set the cluster of the operation
// Catch buffers missed by the main loop
Loop through all buffers which don’t have any flow at all.
Increment the total number of clusters
Set the cluster number to the new cluster
// Catch resources missed by the main loop
Loop through all resources which don’t have any load at all.
Increment the total number of clusters
Set the cluster number to the new cluster
// Finalization
Unlock the function