

Tasks
FrePPLe provides a list of commands that perform actions on the database, the input data and/or the output data.
The commands can be accessed in three different ways:
From the execution screen: Execution screen
From the command line: Command line
Through a web-based API: Remote commands
This section provides an overview of the available actions:
Planning workflows
Administrator commands
Developer commands
The list can be extended with custom commands from extension modules.
Planning workflows
Generate a plan
This option runs the frePPLe planning engine with the input data from the database. The planning results are exported back into the database.
Two main plan types can be distinguished, based on whether you want to see demand OR material, lead time and capacity problems to be shown.
A constrained plan respects all enabled constraints. In case of shortages the demand is planned late or short. No any material or capacity shortages are present in the plan.
An unconstrained plan shows material, capacity and operation problems that prevent the demand from being planned in time. The demand is always met completely and on time.
In both the constrained and unconstrained plans you can select which constraints are considered during plan creation:
- Capacity:Respect the capacity limits of your resources.
- Manufacturing lead time:Don’t generate any manufacturing or distribution orders that start or end in the past.Only confirmed manufacturing and distribution orders are allowed in the past, as these are considered frozen.All approved and proposed manufacturing and distribution orders must start in the future.
- Purchasing lead time:Don’t generate any purchase orders that start or end in the past.Only confirmed purchase orders are allowed in the past, as these are considered frozen.All approved and proposed purchase orders must start in the future.
A separate page provides more details on the Planning algorithm.

frepplectl runplan --constraints=capa,po_lt,mfg_lt --plantype=1 --env=fcst,invplan,balancing,supply
Deprecated (sum of numbers with capa = 4, lt = 1, mfg_lt = 16, po_lt = 32):
frepplectl runplan --constraints=5 --plantype=1 --env=fcst,invplan,balancing,supply
POST /execute/api/runplan/?constraint=capa,po_lt,mfg_lt&plantype=1&env=fcst,invplan,balancing,supply
Deprecated (sum of numbers with capa = 4, lt = 1, mfg_lt = 16, po_lt = 32):
POST /execute/api/runplan/?constraint=5&plantype=1&env=fcst,invplan,balancing,supply
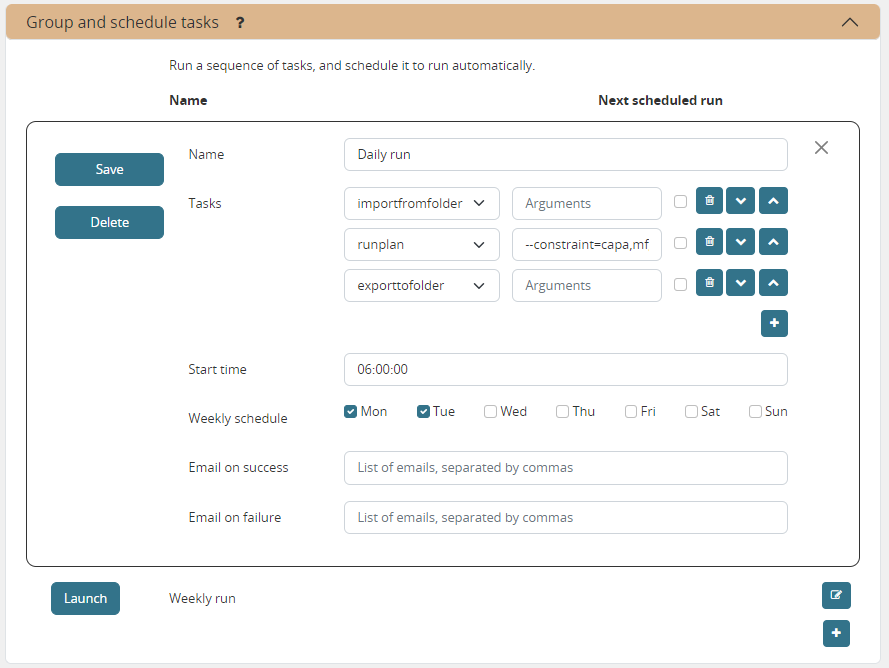
Group and schedule tasks
With this option a user can execute a sequence of steps together as a group.
The execution of the task group can be triggered manually. Or it can be scheduled automatically based on a predefined schedule.
Optionally, a email can be sent out upon failure or success of the execution.
The execution time of the task are specified in a chosen time zone. The next scheduled run you shown in the browser will reflect any offset that may apply.
frepplectl scheduletasks --schedule=my_task_sequence
POST /execute/api/scheduletasks/?schedule=my_task_sequence
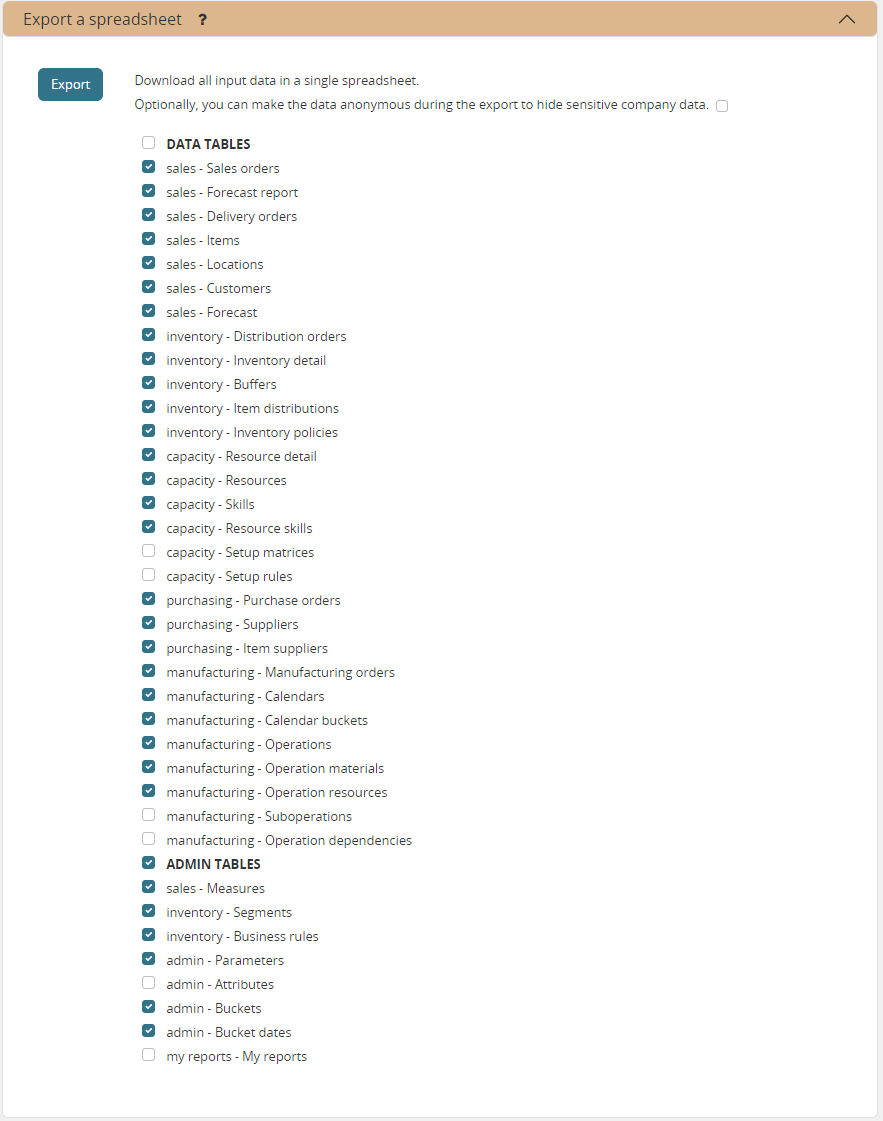
Export a spreadsheet
This task allows you to download the complete model as a single spreadsheet file. The spreadsheet can be opened with Excel or Open Office.
A separate sheet in the workbook is used for each selected entity.
The exported file can be imported back with the task described just below.
Optionally, you can make your dataset anonymous during the export to hide sensitive company data. All entities then get a new name during the export. It remains ABSOLUTELY NECESSARY to carefully review the generated spreadsheet and to remove any sensitive data that is still left, such as descriptions, categories, custom attributes, cost information.
Import a spreadsheet
This task allows you to import an Excel spreadsheet.
A separate sheet in the workbook is used for each selected entity.
The sheet must have the right names - in English or your language. The first row in each sheet must contain the column names.

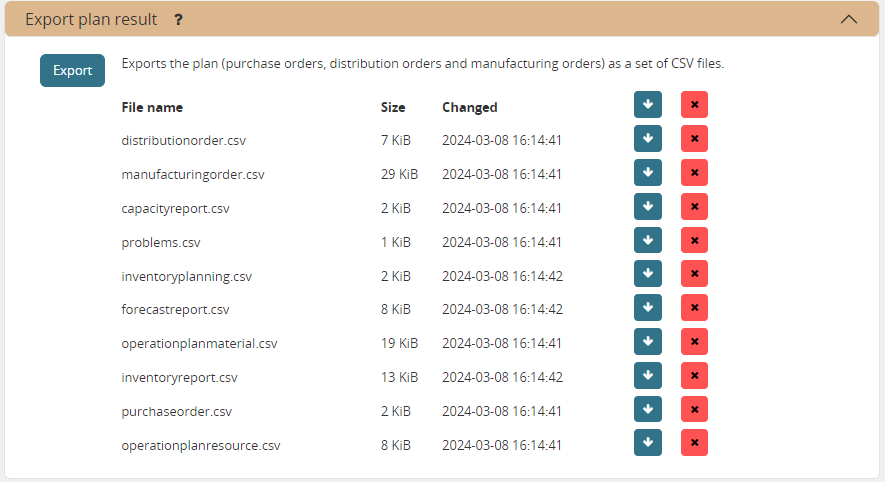
Export plan result
This task allows exporting data to a set of files in CSV or Excel format. The purpose of this task is to help the exchange of information with other systems.
The command can easily by customized to export the results you need.
The files are all placed in a folder UPLOADFILEFOLDER/export/, which can be configured per scenario with the UPLOADFILEFOLDER value in the djangosettings.py file.
The exported files can be accessed from the user interface, or through over a HTTP(S) web interface.
# Export all planning result files:
frepplectl exporttofolder
# Export some planning result files:
frepplectl exporttofolder --files=file1,file2,file3
# Export the planning result files:
POST /execute/api/exporttofolder/
# Export some planning result files:
POST /execute/api/exporttofolder/?files=file1,file2,file3
# Retrieve one of the exported files:
GET /execute/downloadfromfolder/1/<filename>/
# Retrieve one of the exported files after generating it:
GET /execute/downloadfromfolder/1/<filename>/?generate
# Retrieve all exported files:
GET /execute/downloadfromfolder/1/
# Retrieve all exported files after generating them:
GET /execute/downloadfromfolder/1/?generate
# Retrieve the list of all available files, with their size and timestamp
GET /execute/uploadtofolder/1/
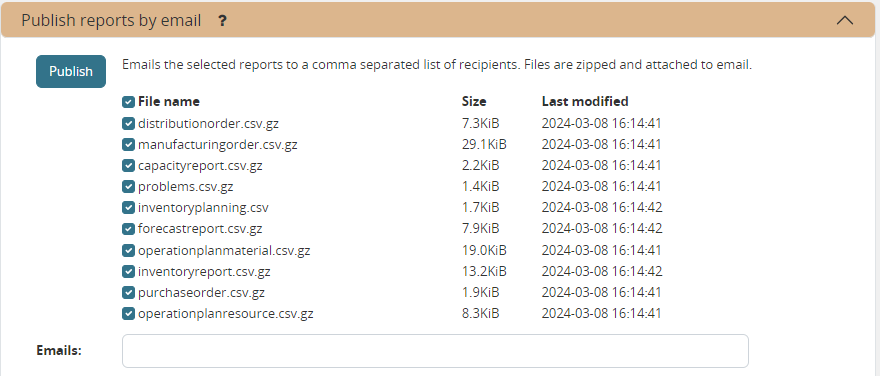
Publish reports by email
Reports that have been exported using Export plan result command can be emailed to one or more recipients.
Recipients have to be separated by a comma in the Emails field.
Selected reports are zipped into a reports.zip file that is attached to the email.
In order to have this command working, the EMAIL parameters in the djangosettings.py file must be properly configured.
frepplectl emailreport [--sender] --recipient --report
POST /execute/api/emailreport/?recipient=recipient1,recipient2...&report=report1,report2,report3...
Publish reports by FTP
Reports that have been exported using Export plan result command can be pushed to a server using a ftp, ftps or sftp connection.
In order to have this command working, the FTP parameters in the djangosettings.py file must be properly configured. Note that, if you are using the SFTP protocol, the destination server needs to be added to the known_hosts file.
frepplectl uploadreport --report=report1,report2,report3
POST /execute/api/uploadreport/?report=report1,report2,report3...
Import data files
This task allows importing data from a set of CSV-formatted files (eventually GZ-compressed). The purpose of this task is to help the exchange of information with other systems.
The files are all placed in a folder that is configurable per scenario with the UPLOADFILEFOLDER in the djangosettings.py configuration file. The log file records all data imports, in addition to any data errors identified during their processing.
The data files to be imported must meet the following criteria:
- The name must match the data object they store: eg demand.csv, item.csv, item.xlsx, item.csv.gzThis is important for frePPLe to understand the correct processing order of the files.
- Multiple files for the same entity can be provided. They will be processed in alphabetical order: eg “demand (1).xlsx”, “demand (2).csv”, “demand.1.csv”, “demand.2.csv”, “demand.extra.xlsx”, “demand.postprocessing.sql”
- The first line of the file should contain the field names. The field name can be in English or the default language configured with the LANGUAGE_CODE setting.
The following file formats are accepted:
The separator in your CSV-files varies with the chosen language: If in your language a comma is used as a decimal separator for numbers, the CSV file will use a semicolon (;) as delimiter. Otherwise a comma (,) is used. See http://en.wikipedia.org/wiki/Decimal_mark
The data file is expected to be encoded in the character encoding defined by the setting CSV_CHARSET (default UTF-8).
The execution screen displays the list of uploaded files. You can download a file (or all files) by clicking on the arrow down button. You can also delete a file by clicking on the red button. The arrow up button will give the user the possibility of selecting multiple files to upload to that folder.
This capability requires superuser privileges. The ability to view or upload files bypasses the access rights configured in the application, so we need to keep the access to the files restricted.
# import all files:
frepplectl importfromfolder
# import some files:
frepplectl importfromfolder --files=file1,file2,file3
# Upload a data file:
POST /execute/uploadtofolder/0/ with data files in multipart/form-data format
# Get an list of available data files with their size and timestamp:
GET /execute/uploadtofolder/0/
# Delete a data file
DELETE /execute/deletefromfolder/0/<filename>/
# Download all your data files:
GET /execute/downloadfromfolder/0/
# Download one of your data files:
GET /execute/downloadfromfolder/0/<filename>/
# Import the data files:
POST /execute/api/importfromfolder/
# Import some data files:
POST /execute/api/importfromfolder/?files=file1,file2,file3
Web service
This action starts or stop the frepple web service which keeps the plan in memory. The web service normally starts automatically, and the use of this command is more an exception.

frepplectl runwebservice
frepplectl stopwebservice
# Upload a data file:
POST /execute/api/runwebservice/
POST /execute/api/stopwebservice/
Scenario management
Scenarios are isolated databases that allow working with multiple datasets. See What-if scenarios for an quick introduction.
This action allows a user to either create copies of a dataset into a what-if scenario or promote the data from a scenario into Production database.
When the data is successfully copied, the status changes from ‘Free’ to ‘In use’. The access to the newly copied scenario is limited to 1) the user who performed the copy plus 2) all superusers of the source scenario.
When the user doesn’t need the what-if scenario any more, it can be released again.
Releasing a scenario can be done from any scenario while copying and promoting actions can only be performed from current scenario to destination scenario.
The label of a scenario, which is displayed in the dropdown list in the upper right hand corner, can also be updated here.
The theme of the user interface can be different for each scenario. This avoids confusion where changes are accidentily applied to an incorrect scenario.
# To copy scenario scenario1 into scenario scenario2:
frepplectl scenario_copy [--force --promote] scenario1 scenario2
# To create scenario1 from a backup file:
frepplectl scenario_copy --dumpfile=\path_to_my_file\scenario_backup.dump default scenario1
# To release scenario scenario1:
frepplectl scenario_release --database=scenario1
# To copy a scenario (including Production) into another scenario:
POST /execute/api/scenario_copy/?copy=1&source=scenario1&destination=scenario2&force=1
# To create scenario1 from a backup file:
POST /execute/api/scenario_copy/?copy=1&source=default&destination=scenario2&dumpfile=\path_to_my_file\scenario_backup.dump
# To release a scenario named scenario1:
POST /scenario1/execute/api/scenario_copy/?release=1
# To promote a scenario named scenario1 into Production (where "default" is the Production name):
POST /execute/api/scenario_copy/?promote=1&source=scenario1&destination=default
Measure management
This option allows a user to copy a measure into another measure.
The destination measure can be either a new measure or an existing measure (that will then be overwritten).

frepplectl measure_copy source_measure destination_measure
POST /execute/api/measure_copy/?source=source_measure&destination=destination_measure
Contact frePPLe support
This task should be used to share your data with the frePPLe support team.
This task dumps the contents of the current database schema to a backup file.
Important: The data in this backup file is not obfuscated. Your dataset will only be used by the frepple developers solely for the purpose of analysing issues. The data is not shared with any third party and will be destroyed after the issue analysis.
The file is created in the log folder configured in the configuration files djangosettings.py. It can be downloaded from the browser and sent to the frePPLe support team.
For security reasons the command is only available to frePPLe superusers.
When executed, the command also removes dumps older than a month to limit the disk space usage. If you want to keep dumps for a longer period of time, you’ll need to copy the backup files to a different location.

frepplectl backup
# Create a backup:
POST /execute/api/backup/
# Download the backup file:
GET /execute/logdownload/<task identifier>/
Clear all data
This will delete all data from the current scenario (except for some internal tables for users, permissions, task log, etc…).
frepplectl empty --models=input.demand,input.operationplan
frepplectl empty --all
POST /execute/api/empty/?models=input.demand,input.operationplan
POST /execute/api/empty/?all=
Import data from odoo
This command is only active when the Odoo integration app is installed. It brings all planning relevant data from Odoo into the frePPLe database.
See Using the connector in frePPLe

frepplectl odoo_import
POST /execute/api/odoo_import/
Pull demand history from odoo
This command is only active when the Odoo integration app is installed. It pulls all the demand history in Odoo into the frePPLe database using the XML RPC API of Odoo.
See Using the connector in frePPLe

frepplectl odoo_pull_so_history
POST /execute/api/odoo_pull_so_history/
Export data to odoo
This command is only active when the Odoo integration app is installed. It publishes part of the plan from frepple into odoo.
The following parts of the plan are exportedto odoo:
proposed purchase orders starting within the next 7 days
proposed distribution orders starting within the next 7 days
proposed manufacturing orders starting within the next 7 days
rescheduled new dates for approved work orders
See Using the connector in frePPLe

frepplectl odoo_export
POST /execute/api/odoo_export/
Administrator commands
Load a dataset in the database
A number of demo datasets are packaged with frePPLe. Using this action you can load one of those in the database.
By default, the dataset is loaded incrementally in the database, without erasing any previous data. A checkbox allows you to purge any existing data before loading the dataset.
Another checkbox allows you to generate a plan after loading the dataset.
You can use the dumpdata command to export a model to the appropriate format and create your own predefined datasets.
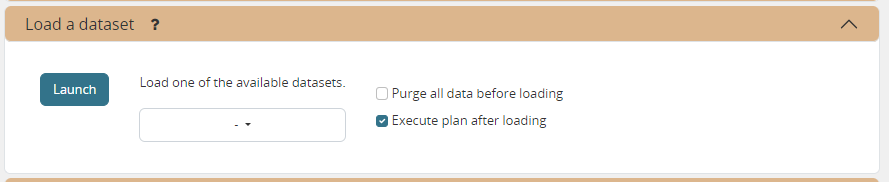
frepplectl loaddata manufacturing_demo
POST /execute/api/loaddata/?fixture=manufacturing_demo
Generate time buckets
Many output reports are displaying the plan results aggregated into time buckets. These time buckets are defined with the tables dates and bucket dates.
For all reports to work correctly and avoid all ambiguity you need to assure the expressions generate a unique name for each bucket. For instance, just using “%y” as day name won’t work.
This tasks allows you to populate these tables in an easy way with buckets with daily, weekly, monthly, quarterly and yearly granularity. Existing bucket definitions for these granularities will be overwritten.
The following arguments are used:
- Week start: Defines the first date of a week.Sunday=0, Monday=1, Tuesday=2, Wednesday=3, Thursday=4, Friday=5, Saturday=6
- Day name, week name, month name, quarter name, year name:Template used to generate a name for the buckets.
Any character can be used in the names and the following format codes can be used:
%a: Weekday as locale’s abbreviated name. Eg: Sun, Mon, …
%A: Weekday as locale’s full name. Eg: Sunday, Monday, …
%w: Weekday as a decimal number, where 0 is Sunday and 6 is Saturday.
%d: Day of the month as a zero-padded decimal number. Eg: 01, 02, …, 31
%b: Month as locale’s abbreviated name. Eg: Jan, Feb, …
%B: Month as locale’s full name. Eg: January, February, …
%m: Month as a zero-padded decimal number. Eg: 01, 02, …, 12
%q: Quarter as a decimal number. Eg: 1, 2, 3, 4
%y: Year without century as a zero-padded decimal number. Eg: 00, 01, …, 99
%Y: Year with century as a decimal number. Eg: 2018, 2019, …
%j: Day of the year as a zero-padded decimal number. Eg: 001, 002, …, 366
%W: Week number of the year as a zero-padded decimal number. Week 1 contains the first Monday.
%V: ISO 8601 week number as a zero-padded decimal number. Week 1 contains the first Thursday.
%%: A literal ‘%’ character.
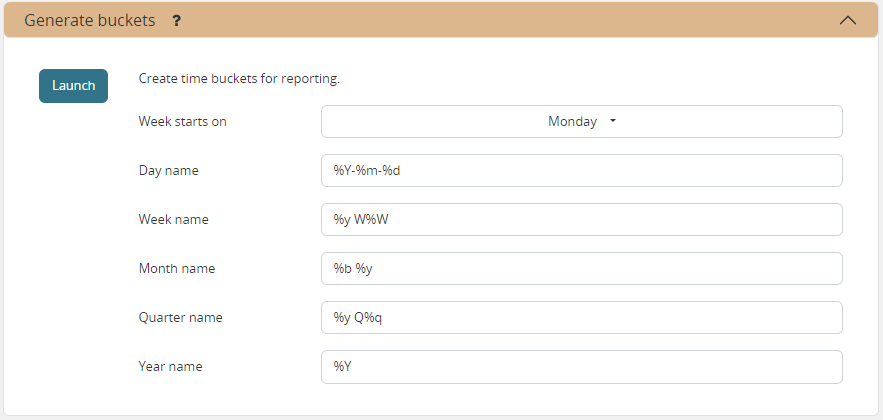
frepplectl createbuckets --weekstart=1 --format-day="%Y-%m-%d" --format-week="%y W%W" --format-month="%b %y" --format-quarter="%y Q%q" --format-year="%Y"
POST /execute/api/createbuckets/?weekstart=1
Create the PostgreSQL database(s)
This command will create the PostgreSQl databases for frePPLe.
If the database already exists you will be prompted to confirm whether you really to loose all data in the existing database. When confirmed that database will dropped and recreated.
# Create all scenario databases
frepplectl createdatabase
# Recreate only a single database
frepplectl createdatabase --database=scenario3
Create or migrate the database schema
Update the database structure to the latest release.
# Migrate all scenarios that are currently in use
frepplectl migrate
# Migrate a specific scenario database
frepplectl migrate --database=default
frepplectl migrate --database=scenario1
Restore a database backup
This command erases the existing content of a database and restores the contents of a postgresql database dump file.
The database dump file can either be created with the Contact frePPLe support command, or with the PostgreSQL pg_dump command. When using pg_dump, you need to use the “custom format”.
The scenario management command allows a user to restore a backup in a specific scenario database
frepplectl restore database_dump_file
Create a new superuser
This command creates a new user with full access rights.
frepplectl createsuperuser new_user_name
Change a user’s password
This command changes the password of a certain user.
frepplectl changepassword user_name
Remove all database objects
This command completely empties all tables in the database, including all log, users, user preferences, permissions, etc…
A complete reset of the database is not very common. In most situations the command described above to empty the database is sufficient. It empties the data tables, but leaves the important configuration information intact.
frepplectl flush
Generate an API token
This command generates a JWT authentication token that can be used for API calls.
frepplectl generatetoken user_name --expiry=365
Developer commands
Database shell prompt
This command runs an interactive SQL session on the PostgreSQL database.
frepplectl dbshell --database=default
Python command prompt
This command runs an interactive Python interpreter session.
frepplectl shell
Dump a frozen dataset
Outputs to standard output all data in the database (or a part of it).
When the output file of this command is placed in a fixtures subfolder it can be used by the loaddata command described above. We recommend you review and cleanse the output carefully, to avoid that the frozen dataset contains unnecessary data.
frepplectl dumpdata --database=scenario1
Run the test suite
Run the test suite for the user interface.
frepplectl test freppledb
Run the development web server
Run a development web server, which automatically reloads when code is changed.
For production use this web server doesn’t scale enough.
frepplectl runserver
Generate a sample model
Populate the database with a configurable dataset. Command line arguments control the depth and complexity of the bill of material, the number of resources and their average load, the average lead times, the number of demands.
The command thus allows to quickly generate a sample model, and to verify its scalability with varying size and complexity.
This command is intended for academic and research purposes. The script can easily be updated to create sample models in the structure you wish.
frepplectl createmodel --level=3 --cluster=100 --demand=10
Estimate historical forecast accuracy
This command estimates the forecast accuracy over the past periods.
This is achieved by turning back the clock a number of buckets ago. We compute the forecast with the demand history we would have had available at that time. Comparing the actual sales and the forecasted sales in that period allows us to measure the forecast accuracy. This calculation is then repeated for each bucket to follow.
This command is intended for academic and research purposes. The script can easily be updated to perform more advanced forecast accuracy studies.
frepplectl forecast_simulation
Simulate the execution of the plan
This command simulates the execution of the plan. The command allows detailed studies of the stability and robustness of the plan in the presence of various disturbances.
The command iterates over a number of time periods and performs the following steps in each period:
Advance the current date
Call a custom function “start_bucket”
- Open new sales orders from customersCustom code can be added here to represent the typical ordering pattern of customers, and the occasional rush orders.
Generate a constrained frePPLe plan
Confirm new purchase orders from the frePPLe plan
Confirm new production orders from the frePPLe plan
Confirm new distribution orders from the frePPLe plan
- Receive material from purchase ordersCustom code can be added here to simulate late or early deliveries from your suppliers.
- Finish production from manufacturing ordersCustom code can be added here to simulate production delays, machine breakdowns, rework and other production disturbances.
- Receive material from distribution ordersCustom code can be added here to simulate late or early deliveries between locations in the warehouse.
Ship open sales orders to customers
- Call a custom function “end_bucket”This function will typically be used to collect performance statistics of the period just simulated.
This command is intended for academic and research purposes. The script needs to be tailored carefully to model a realistic level of disturbances in your model and collect the performance metrics that are relevant.
frepplectl simulation